Burpsuite 新的爬虫机制 | Burp’s new crawler
Burp’s new crawler
https://portswigger.net/blog/burps-new-crawler
Dafydd Stuttard @PortSwigger
历史上的模型
Spider 工具维护一个待处理请求队列。它通过发出每个请求的队列,查找新链接和表单的响应,并将相关请求添加到队列。这种方法对于每个函数具有唯一且稳定的 URL 的站点非常有效,使用简单的基于 cookie 的会话处理,在每个响应中返回确定性内容,并且模型中不包含服务器端状态。但今天大多数应用程序都不是这样的。所以我们用更好的东西取代 Spider 工具。
新的模型
Burp 的新爬虫使用了完全不同的模型。它通过单击链接并提交输入,以与使用浏览器的用户相同的方式在目标应用程序周围导航。它以有向图的形式构建应用程序内容和功能的映射,表示应用程序中的不同位置以及这些位置之间的链接。
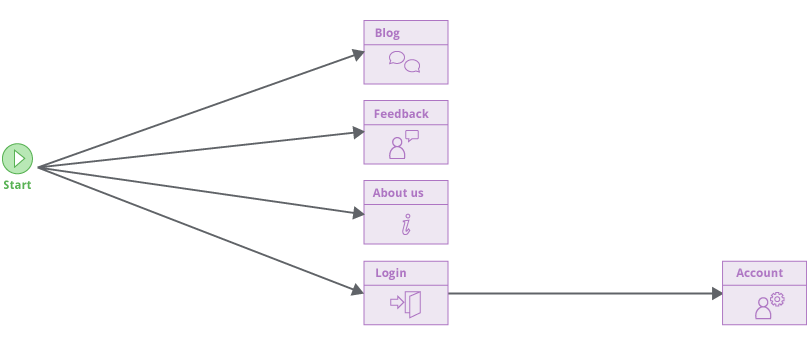
新的爬网程序不会假设应用程序使用的 URL 结构。根据其内容识别(并在以后重新识别)位置,而不是用于访问它们的URL。这使爬虫能够可靠地处理将短暂数据(如 CSRF 令牌或缓存破坏者)放入URL路径的现代应用程序。即使每个链接中的整个 URL 在每种情况下都发生了变化,抓取工具仍会构建准确的网站地图(sitemap)
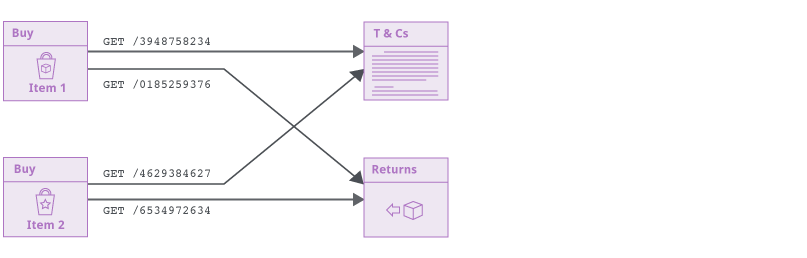
该方法还允许新爬虫根据应用程序的状态或用户与其的交互来处理使用相同URL到达 Web 应用程序 的 不同位置。
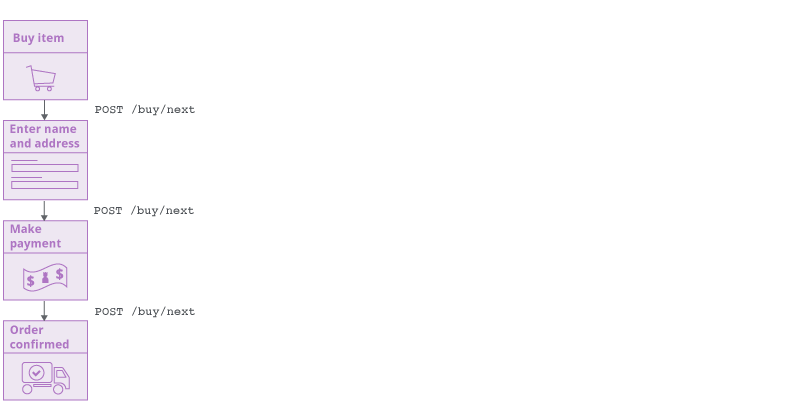
旧Spider使用待处理请求队列跟踪其剩余工作。新的爬虫必须以不同的方式跟踪其剩余的工作。当爬虫在导航并构建目标应用程序的覆盖范围时,它会跟踪图中尚未完成的边缘。这些代表在应用程序中观察到但尚未访问的链接(或其他导航过渡)。但是抓取工具永远不会“跳转”到待处理的链接并在上下文中访问它。相反,它要么通过其当前位置的链接进行导航,要么还原到起始位置并从那里导航。这会尽可能地复制普通用户对浏览器的操作。
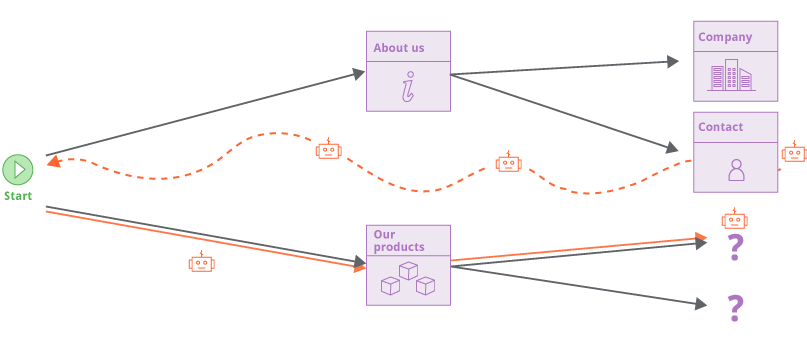
以对 URL 结构不做任何假设的方式进行爬网在处理现代 Web 应用程序时非常有效,但可能会导致爬虫抓到”太多”内容。
现代网站通常包含大量多余的导航路径(通过页脚,汉堡菜单等),这意味着所有内容都与其他所有内容直接相关。新的爬虫使用各种技术来解决这个问题:它建立了已经访问过的位置的链接指纹,以避免冗余访问它们; 它以广度优先的顺序爬行,优先发现新内容; 它具有可配置的黑名单(受限访问的目录),可以限制爬行的范围。这些措施还有助于正确处理”无限”的应用程序,例如日历。
在接下来的几天里,我们将描述在此基础上构建的新爬虫的各种其他强大功能。
后续文章
Automatic session handling
https://portswigger.net/blog/automatic-session-handling
Detecting changes in application state
https://portswigger.net/blog/detecting-changes-in-application-state
Crawling with multiple logins
https://portswigger.net/blog/crawling-with-multiple-logins
Automatically maintaining session during scans
https://portswigger.net/blog/automatically-maintaining-session-during-scans
Crawling volatile content
https://portswigger.net/blog/crawling-volatile-content
Multi-phase scanning
https://portswigger.net/blog/multi-phase-scanning
Leave a Reply